In diesem Blog-Beitrag geht es darum, wie man mithilfe von Python und SPARQL Wikidata durchsucht und anschließend die gefundenen Georeferenzen auf einer Karte plottet. Ziel ist es, einer Karte mit all denjenigen zu erstellen, die am 26. November Geburtstag haben und vor 1900 geboren worden sind.
Zuerst binden wir die notwendigen Bibliotheken ein.
import requests
import pandas as pd
Jetzt erstellen wir einen String, mit der SPARQL-Abfrage: Wir suchen den Name der Person, ihr Geburtsdatum (26. November vor 1900), den Geburtsort und seine Koordinaten.
Danach legen wir die URL für die Suchabfrage fest.
query = """
SELECT ?name ?place ?placeLabel ?coord ?date
WHERE {
?person wdt:P1477 ?name; # Irgendeine Person mit der Eigenschaft "hat Namen"
wdt:P569 ?date; # Person mit Geburtsdatum
wdt:P19 ?place. # Person mit Geburtsort
?place wdt:P625 ?coord. # Von dem Ort die Koordinaten
FILTER (datatype(?date) = xsd:dateTime) # Das Datum hat das Format eines Datums
FILTER (month(?date) = 11) # 11. Monat = November
FILTER (day(?date) = 26) # 26. Tag des Monats
FILTER (year(?date) <= 1900) # Jahresbereich eingrenzen
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
"""
url = 'https://query.wikidata.org/sparql'
Anschließend übergeben wir den String an die Such-URL. Die Serverantwort ist ein in JSON serialisiertes Dictionary.
data = requests.get(url, params={'query': query, 'format': 'json'}).json()
# data
Im JSON sind die uns interessierenden Daten unter ‘results’ und ‘bindings’ abgelegt. Wir erstellen eine neue Liste namens ‘personen’ und tragen dort von jedem Eintrag die jeweiligen Werte aus name, birthday, place und coord ein. Diese Bezeichnungen stammen aus unserer SPARQL-Abfrage.
personen = []
for item in data['results']['bindings']:
personen.append({'name': item['name']['value'],
'birthday': item['date']['value'],
'place': item['placeLabel']['value'],
'coord': item['coord']['value']}
)
Als Ergebnis erhalten wir eine Liste, die für jede Person ein Dictionnary mit den jeweiligen Angaben einen als Eintrag hat. Hier ein Auszug aus der Liste mit den ersten fünf Einträgen.
[{'name': 'Pierre Joseph Maxime Théodore Guillerand',
'birthday': '1877-11-26T00:00:00Z',
'place': 'Dompierre-sur-Héry',
'coord': 'Point(3.5642 47.2647)'},
{'name': 'Flegenheimer',
'birthday': '1874-11-26T00:00:00Z',
'place': 'Geneva',
'coord': 'Point(6.15 46.2)'},
{'name': 'Charles William Gillet',
'birthday': '1840-11-26T00:00:00Z',
'place': 'Addison',
'coord': 'Point(-77.233888888 42.103888888)'},
{'name': 'Thomas Dyke Acland Tellefsen',
'birthday': '1823-11-26T00:00:00Z',
'place': 'Trondheim',
'coord': 'Point(10.4 63.44)'},
{'name': 'Frederick Smith',
'birthday': '1898-11-26T00:00:00Z',
'place': 'Waterfoot',
'coord': 'Point(-2.251 53.692)'}]
Jetzt übertragen wir die Liste in einen Dataframe.
df = pd.DataFrame(personen)
Der Dataframe ist eine Art tabellarischer Repräsentanz der Listendaten. Der Übersicht halber zeige ich wieder nur einen Ausschnitt:
| name | birthday | place | coord | |
|---|---|---|---|---|
| 0 | Pierre Joseph Maxime Théodore Guillerand | 1877-11-26T00:00:00Z | Dompierre-sur-Héry | Point(3.5642 47.2647) |
| 1 | Flegenheimer | 1874-11-26T00:00:00Z | Geneva | Point(6.15 46.2) |
| 2 | Charles William Gillet | 1840-11-26T00:00:00Z | Addison | Point(-77.233888888 42.103888888) |
| 3 | Thomas Dyke Acland Tellefsen | 1823-11-26T00:00:00Z | Trondheim | Point(10.4 63.44) |
| 4 | Frederick Smith | 1898-11-26T00:00:00Z | Waterfoot | Point(-2.251 53.692) |
Das Format in der Spalte birthday steht noch nicht im Datumsformat. Das ändern wir mit dem folgenden Code.
df['birthday'] = pd.to_datetime(df['birthday'])
df.tail()
| name | birthday | place | coord | |
|---|---|---|---|---|
| 36 | Guido Rocco | 1886-11-26 00:00:00+00:00 | Naples | Point(14.25 40.833333333) |
| 37 | José del Castillo y Soriano | 1849-11-26 00:00:00+00:00 | Madrid | Point(-3.691944444 40.418888888) |
| 38 | Christian Célestin Joseph Dauvergne | 1890-11-26 00:00:00+00:00 | Boulogne-Billancourt | Point(2.241388888 48.835277777) |
| 39 | Pierre Albert Ode | 1811-11-26 00:00:00+00:00 | Pont-Saint-Esprit | Point(4.648333333 44.256388888) |
| 40 | Михаил Цветков Минев | 1874-11-26 00:00:00+00:00 | Lovech | Point(24.717222222 43.134166666) |
Nun greifen wir auf jeden Eintrag in der coord-Spalte, übergeben den Wert an eine Lambda-Funktion, entfernen den String ‘Point()’, erstellen eine Liste und greifen auf den ersten Wert zurück, den wir im Dataframe unter lon ablegen.
df['lon'] = df['coord'].apply(lambda x: x.strip('Point()').split()[0])
df['lon'] = df['lon'].astype(float)
0 3.564200
1 6.150000
2 -77.233889
3 10.400000
4 -2.251000
5 -70.266667
6 -75.483300
7 -75.483300
8 2.176944
9 4.426900
10 12.568889
11 3.057500
12 -70.666667
13 -1.613333
14 -4.766667
15 30.316667
16 8.679722
17 -75.683300
18 4.850900
19 144.961389
20 15.389777
21 12.983300
22 1.951400
23 -72.383333
24 3.613611
25 -73.098720
26 17.971154
27 -6.200967
28 10.328000
29 -3.691944
30 16.633333
31 2.176944
32 10.000000
33 -73.692600
34 15.436900
35 2.666667
36 14.250000
37 -3.691944
38 2.241389
39 4.648333
40 24.717222
Name: lon, dtype: float64
Das gleiche machen wir für die Spalte lat.
df['lat'] = df['coord'].apply(lambda x: x.strip('Point()').split()[1])
df['lat'] = df['lat'].astype(float)
0 47.264700
1 46.200000
2 42.103889
3 63.440000
4 53.692000
5 43.666667
6 44.700000
7 44.700000
8 41.382500
9 43.800300
10 55.676111
11 50.631944
12 -33.450000
13 54.977778
14 37.883333
15 59.950000
16 50.113611
17 -11.416700
18 45.774300
19 -37.820556
20 49.911045
21 45.883300
22 49.486400
23 -38.050000
24 51.499722
25 43.254800
26 49.471800
27 36.466607
28 44.801472
29 40.418889
30 47.233333
31 41.382500
32 53.550000
33 45.441889
34 46.243600
35 42.166667
36 40.833333
37 40.418889
38 48.835278
39 44.256389
40 43.134167
Name: lat, dtype: float64
Als letzten Schritt binden wir plotly.express ein und erstellen eine Karte mit den zuvor gewonnen Geokordinaten:
import plotly.express as px
px.scatter_geo(df, lon='lon', lat='lat', scope='europe', text='place')
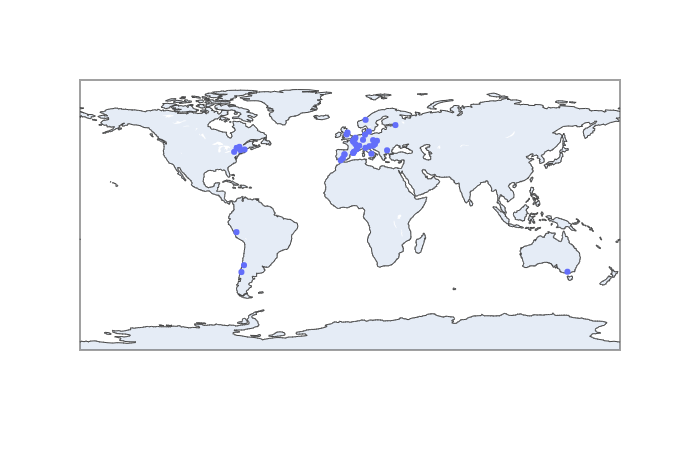 Plotly-Plot mit Geburtsorten.
Plotly-Plot mit Geburtsorten.